Быстрая сортировка (англ. quicksort), часто называемая qsort по имени реализации в стандартной библиотеке языка Си — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром в 1960 году. Один из быстрых известных универсальных алгоритмов сортировки массивов (в среднем O(n log n) обменов при упорядочении n элементов), хотя и имеющий ряд недостатков.
В программе предлагаемой Википедией и на всех просторах рунета придется исправить ошибочку...Краткое описание алгоритма
- выбрать элемент, называемый опорным.
- сравнить все остальные элементы с опорным, на основании сравнения разбить множество на три — «меньшие опорного», «равные» и «большие», расположить их в порядке меньшие-равные-большие.
- повторить рекурсивно для «меньших» и «больших».
Алгоритм
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:- Выбираем в массиве некоторый элемент, который будем называть опорным элементом. С точки зрения корректности алгоритма выбор опорного элемента безразличен. С точки зрения повышения эффективности алгоритма выбираться должна медиана, но без дополнительных сведений о сортируемых данных её обычно невозможно получить. Известные стратегии: выбирать постоянно один и тот же элемент, например, средний или последний по положению; выбирать элемент со случайно выбранным индексом.
- Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него. Обычный алгоритм операции:
- Два индекса — l и r, приравниваются к минимальному и максимальному индексу разделяемого массива соответственно.
- Вычисляется индекс опорного элемента m.
- Индекс l последовательно увеличивается до тех пор, пока l-й элемент не превысит опорный.
- Индекс r последовательно уменьшается до тех пор, пока r-й элемент не окажется меньше либо равен опорному.
- Если r = l — найдена середина массива — операция разделения закончена, оба индекса указывают на опорный элемент.
- Если l < r — найденную пару элементов нужно обменять местами и продолжить операцию разделения с тех значений l и r, которые были достигнуты. Следует учесть, что если какая-либо граница (l или r) дошла до опорного элемента, то при обмене значение m изменяется на r-й или l-й элемент соответственно.
- Рекурсивно упорядочиваем подмассивы, лежащие слева и справа от опорного элемента.
- Базой рекурсии являются наборы, состоящие из одного или двух элементов. Первый возвращается в исходном виде, во втором, при необходимости, сортировка сводится к перестановке двух элементов. Все такие отрезки уже упорядочены в процессе разделения.
Интересно, что Хоар разработал этот метод применительно к машинному переводу: дело в том, что в то время словарь хранился на магнитной ленте, и если упорядочить все слова в тексте, их переводы можно получить за один прогон ленты. Алгоритм был придуман Хоаром во время его пребывания в Советском Союзе, где он обучался в Московском университете компьютерному переводу и занимался разработкой русско-английского разговорника.[1]
//алгоритм на языке java
public static void qSort(int[] A, int low, int high) {
int i = low;
int j = high;
int x = A[(low+high)/2];
do {
while(A[i] < x) ++i;
while(A[j] > x) --j;
if(i <= j){
int temp = A[i];
A[i] = A[j];
A[j] = temp;
i++; j--;
}
} while(i <= j);
if(low < j) qSort(A, low, j);
if(i < high) qSort(A, i, high);
}
|
//алгоритм на языке pascal
//при первом вызове 2-ой аргумент должен быть равен 0
//3-ий аргумент должен быть равен числу элементов массива минус 1
procedure qSort(var ar:array of real; low,high:integer);
var i,j:integer;
m,wsp:real;
begin
i:=low;
j:=high;
m:=ar[(i+j) div 2];
repeat
while(ar[i]<m) do i:=i+1;
while(ar[j]>m) do j:=j-1;
if(i<=j) then begin
wsp:=ar[i];
ar[i]:=ar[j];
ar[j]:=wsp;
i:=i+1;
j:=j-1;
end;
until (i>j);
if(low<j) then qSort(ar,low,j);
if(i<high) then qSort(ar,i,high);
end;
Пример: 60,79, 82, 58, 39, 9, 54, 92, 44, 32 60,79, 82, 58, 39, 9, 54, 92, 44, 32 9,79, 82, 58, 39, 60, 54, 92, 44, 32 9,79, 82, 58, 39, 60, 54, 92, 44, 32 9, 32, 82, 58, 39, 60, 54, 92, 44, 79 9, 32, 44, 58, 39, 60, 54, 92, 82, 79 9, 32, 44, 58, 39, 54, 60, 92, 82, 79 9, 32, 44, 58, 39, 92, 60, 54, 82, 79 9, 32, 44, 58, 39, 54, 60, 79, 82, 92 9, 32, 44, 58, 54, 39, 60, 79, 82, 92 9, 32, 44, 58, 60, 39, 54, 79, 82, 92 9, 32, 44, 58, 54, 39, 60, 79, 82, 92 9, 32, 44, 58, 54, 39, 60, 79, 82, 92 9, 32, 44, 58, 54, 39, 60, 79, 82, 92 9, 32, 39, 58, 54, 44, 60, 79, 82, 92 9, 32, 39, 58, 54, 44, 60, 79, 82, 92 9, 32, 39, 44, 54, 58, 60, 79, 82, 92 9, 32, 39, 44, 58, 54, 60, 79, 82, 92 9, 32, 39, 44, 54, 58, 60, 79, 82, 92 9, 32, 39, 44, 54, 58, 60, 79, 92, 82 9, 32, 39, 44, 54, 58, 60, 79, 82, 92 |
Оценка эффективности
QuickSort является существенно улучшенным вариантом алгоритма сортировки с помощью прямого обмена (его варианты известны как «Пузырьковая сортировка» и «Шейкерная сортировка»), известного, в том числе, своей низкой эффективностью. Принципиальное отличие состоит в том, что после каждого прохода элементы делятся на две независимые группы. Любопытный факт: улучшение самого неэффективного прямого метода сортировки дало в результате эффективный улучшенный метод.- Лучший случай. Для этого алгоритма самый лучший случай — если в каждой итерации каждый из подмассивов делился бы на два равных по величине массива. В результате количество сравнений, делаемых быстрой сортировкой, было бы равно значению рекурсивного выражения CN = 2CN/2+N, что в явном выражении дает примерно N lg N сравнений. Это дало бы наименьшее время сортировки.
- Среднее. Даёт в среднем O(n log n) обменов при упорядочении n элементов. В реальности именно такая ситуация обычно имеет место при случайном порядке элементов и выборе опорного элемента из середины массива либо случайно.
На практике (в случае, когда обмены являются более затратной операцией, чем сравнения) быстрая сортировка значительно быстрее, чем другие алгоритмы с оценкой O(n lg n), по причине того, что внутренний цикл алгоритма может быть эффективно реализован почти на любой архитектуре. 2CN/2 покрывает расходы по сортировке двух полученных подмассивов; N — это стоимость обработки каждого элемента, используя один или другой указатель. Известно также, что примерное значение этого выражения равно CN = N lg N. - Худший случай. Худшим случаем, очевидно, будет такой, при котором на каждом этапе массив будет разделяться на вырожденный подмассив из одного опорного элемента и на подмассив из всех остальных элементов. Такое может произойти, если в качестве опорного на каждом этапе будет выбран элемент либо наименьший, либо наибольший из всех обрабатываемых.
Худший случай даёт O(n²) обменов. Но количество обменов и, соответственно, время работы — это не самый большой его недостаток. Хуже то, что в таком случае глубина рекурсии при выполнении алгоритма достигнет n, что будет означать n-кратное сохранение адреса возврата и локальных переменных процедуры разделения массивов. Для больших значений n худший случай может привести к исчерпанию памяти во время работы алгоритма. Впрочем, на большинстве реальных данных можно найти решения, которые минимизируют вероятность того, что понадобится квадратичное время.
Улучшения
- При выборе опорного элемента из данного диапазона случайным образом худший случай становится очень маловероятным и ожидаемое время выполнения алгоритма сортировки — O(n lg n).
- Выбирать опорным элементом средний из трех (первого, среднего и последнего элементов). Такой выбор также направлен против худшего случая.
- Во избежание достижения опасной глубины рекурсии в худшем случае (или при приближении к нему) возможна модификация алгоритма, устраняющая одну ветвь рекурсии: вместо того, чтобы после разделения массива вызывать рекурсивно процедуру разделения для обоих найденных подмассивов, рекурсивный вызов делается только для меньшего подмассива, а больший обрабатывается в цикле в пределах этого же вызова процедуры. С точки зрения эффективности в среднем случае разницы практически нет: накладные расходы на дополнительный рекурсивный вызов и на организацию сравнения длин подмассивов и цикла — примерно одного порядка. Зато глубина рекурсии ни при каких обстоятельствах не превысит log2n, а в худшем случае вырожденного разделения она вообще будет не более 2 — вся обработка пройдёт в цикле первого уровня рекурсии.
- Разбивать массив не на две, а на три части (см. Dual Pivot Quicksort).
Достоинства и недостатки
Достоинства:- Один из самых быстродействующих (на практике) из алгоритмов внутренней сортировки общего назначения.
- Прост в реализации.
- Требует лишь
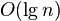 дополнительной памяти для своей работы. (Не улучшенный рекурсивный алгоритм в худшем случае
дополнительной памяти для своей работы. (Не улучшенный рекурсивный алгоритм в худшем случае  памяти)
памяти) - Хорошо сочетается с механизмами кэширования и виртуальной памяти.
- Существует эффективная модификация (алгоритм Седжвика) для сортировки строк — сначала сравнение с опорным элементом только по нулевому символу строки, далее применение аналогичной сортировки для «большего» и «меньшего» массивов тоже по нулевому символу, и для «равного» массива по уже первому символу.
- Сильно деградирует по скорости (до
 ) при неудачных выборах опорных элементов, что может случиться при неудачных входных данных. Этого можно избежать, используя такие модификации алгоритма, как Introsort, или вероятностно, выбирая опорный элемент случайно, а не фиксированным образом.
) при неудачных выборах опорных элементов, что может случиться при неудачных входных данных. Этого можно избежать, используя такие модификации алгоритма, как Introsort, или вероятностно, выбирая опорный элемент случайно, а не фиксированным образом. - Наивная реализация алгоритма может привести к ошибке переполнения стека, так как ей может потребоваться сделать вложенных рекурсивных вызовов. В улучшенных реализациях, в которых рекурсивный вызов происходит только для сортировки меньшей из двух частей массива, глубина рекурсии гарантированно не превысит .
- Неустойчив — если требуется устойчивость, приходится расширять ключ.